Containerisation Standards
This section describes a set of standards, conventions and guidelines for building, integrating and maintaining container technologies. For a hands on training please check :
Containerisation and Orchestration Concept PDF
Containerisation and Orchestration exercises
Warning
Information regarding examples on these pages may be out of date
Overview of Standards
These standards, best practices and guidelines are based on existing industry standards and tooling. The main references are:
The standards are broken down into the following areas:
Structuring applications in a containerised environment - general guidelines for breaking up application suites for running in a containerised way
Defining and building container images - how to structure image definitions, and map your applications onto the image declaration
Running containerised applications - interfacing your application with the container run time environment
Throughout this documentation, Docker is used as the reference implementation with the canonical version being Docker 18.09.4 CE API version 1.39, however the aim is to target compliance with the OCI specifications so it is possible to substitute in alternative Container Engines, and image build tools that are compatible.
Cheatsheet
A Container Standards CheatSheet is provided at the end of this document as a quick guide to standards and conventions elaborated on throughout this document.
Structuring applications in a Containerised Environment
How does containerisation work
Containerisation is a manifestation of a collection of features of the Linux kernel and OS based on:
Capabilities (CAPS) - POSIX 1003.1e capabilities - predate namespaces, but genesis for Linux unknown - approximately Kernel 2.2 onwards
Cgroups - introduced in January 2008
File-system magic - such as pivot_root, and bind mounting first appeared in Linux 2.4 - circa 2001
Namespaces - introduced in 2002
These features combine to give a form of lightweight virtualisation that runs directly in the host system Kernel of Linux, where the container is typically launched by a Container Engine such as Docker.
Namespaces create the virtualisation effect by switching the init process (PID 1) of a container into a separate namespace of the Kernel for processes, network stacks and mount tables so as to isolate the container from all other running processes in the Kernel. Cgroups provide a mechanism for controlling resource allocation eg: Memory, CPU, Net, and IO quotas, limits, and priorities. Capabilities are used to set the permissions that containerised processes have for performing system calls such as IO. The file-system magic performed with pivot_root recasts the root of the file-system for the container init process to a new mount point, typically the root of the container image directory tree. Then, bind mounting enables sharing file-system resources into a container.
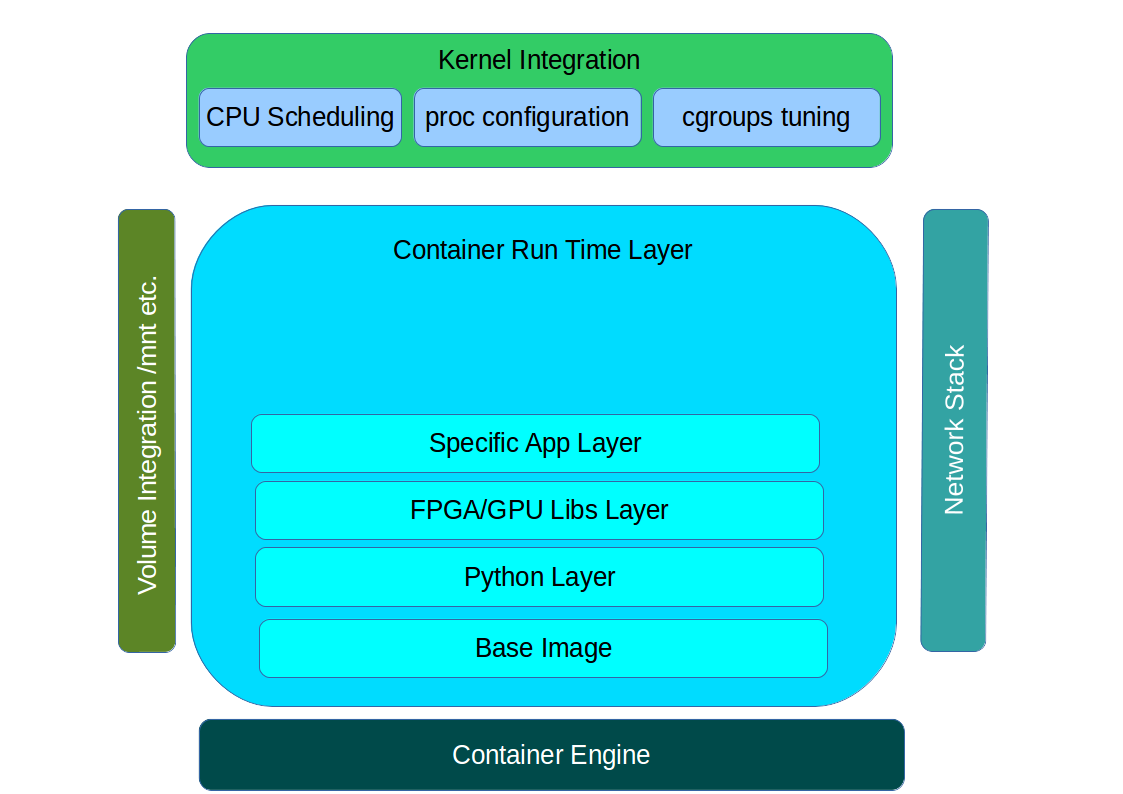
The basic anatomy of a container and how it interfaces with host at run time.
Container Image
The Linux Kernel features make it possible for the container virtualisation to take place in the Kernel, and to have controls placed on the runtime of processes within that virtualisation. The container image is the first corner stone of the software contract between the developer of a containerised application and the Container Engine that implements the Virtualisation. The image is used to encapsulate all the dependencies of the target application including executables, libraries, static configuration and sometimes static data.
The OCI Image specification defines a standard for constructing the root file-system that a containerised application is to be launched from. The file-system layout of the image is just like the running application would expect and need as an application running on a virtual server. This can be as little as an empty / (root) directory for a fully statically linked executable, or it could be a complete OS file-system layout including /etc, /usr, /bin, /lib etc. - whatever the target application needs.
According to the OCI specification, these images are built up out of layers that typically start with a minimal OS such as AlpineLinux, with successive layers of modification that add libraries, configuration and other application dependencies.
At container launch, the image layers of the specified image are stacked up in ascending order using a Union File-System. This creates a complete virtual file-system view, that is read only (if an upper layer has the same file as a lower layer, the lower layer is masked). Over the top of this file-system pancake stack a final read/write layer is added to complete the view that is passed into the container as it’s root file-system at runtime.
Network Integration
Different Container Engines deal with networking in varying ways at runtime, but typically it comes in two flavours:
host networking - the host OS network stack is pushed into the container
a separate virtual network is constructed and bridged into the container namespace
There are variations available within Docker based on overlay, macvlan and custom network plugins that conform to the CNI specification.
Hostname, and DNS resolution is managed by bind mounting a custom /etc/hosts and /etc/resolv.conf into the container at runtime, and manipulating the UTS namespace.
Storage Integration
External storage required at runtime by the containerised application is mapped into the container using bind mounting. This takes a directory location that is already present on the host system, and maps it into the specified location within the container file-system tree. This can be either files or directories. The details of how specialised storage is made available to the container is abstracted by the Container Engine which should support the CSI specification for drivers integrating storage solutions. This is the same mechanism used to share specialised devices eg: /dev/nvidia0 into a container.
Structuring Containerised Applications
Each containerised application should be a single discrete application. A good test for this is:
is there a single executable entry point for the container?
is the running process fulfilling a single purpose?
is the process independently maintainable and upgradable?
is the running process independently scalable?
For example, iperf, or apache2 as separate containerised applications are correct, but putting NGiNX and PostgreSQL in a single container is wrong. This is because NGiNX and PostgreSQL should be independently maintained, upgraded and scaled, an init process handler would be required to support multiple parent processes, and signals would not be correctly propagated to these parent processes (eg: Postgres and NGiNX) from the Container Engine.
A containerised application should not need a specialised multi-process init process such as supervisord. As soon as this is forming part of the design, there should almost always be an alternative where each application controlled by the init process is put into a separate container. Often this can be because the design is trying to treat a container like a full blown Virtual Machine through adding sshd, syslog and other core OS services. This is not an optimal design because these services will be multiplied up with horizontal scaling of the containerised application wasting resources. In both these example cases, ssh is not required because a container can be attached to for diagnostic purposes eg: docker exec ..., and it is possible to bind mount /dev/log from the host into a container or configure the containerised application to point to syslog over TCP/UDP.
Take special care with signal handling - the Container Engine propagates signals to init process which should be the application (using the EXEC for of entry point). If not it will be necessary to ensure that what ever wrapper (executable, shell script etc.) is used propagates signals correctly to the actual application in the container. This is particularly important at termination time where the Engine will typically send a SIGHUP waiting for a specified timeout and then following up with a SIGKILL. This could be harmful to stateful applications such as databases, message queues, or anything that requires an orderly shutdown.
A container image among other things, is a software packaging solution, so it is natural for it to follow the same Software Development Life Cycle as the application held inside. This also means that it is good practice for the released container image versions to map to the released application versions. An example of this in action is the NGiNX Ingress Controller releases. By extension, this also leads to having one Git repository and container image per application in order to correctly manage independent release cycles.
Defining and Building Container Images
The core of a containerised application is the image. According to the OCI specification, this is the object that encapsulates the executable and dependencies, external storage (VOLUME) and the basics of the launch interface (the ENTRYPOINT and ARGS).
The rules for building an image are specified in the Dockerfile which forms a kind of manifest. Each rule specified creates a new layer in the image. Each layer in the image represents a kind of high watermark of an image state which can ultimately be shared between different image builds. Within the local image cache, these layer points can be shared between running containers because the image layers are stacked as a read only UnionFS. This Immutability is a key concept in containers. containers should not be considered mutable and therefore precious. The goal is that it should be possible to destroy and recreate them with (little or) no side effects.
If there is any file-system based state requirement for a containerised application, then that requirement should be satisfied by mounting in external storage. This will mean that the container can be killed and restarted at anytime, giving a pathway to upgrade-ability, maintainability and portability for the application.
The Image
When structuring the image build eg: Dockerfile, it is important to:
minimise the size of the image, which will speed up the image pull from the repository and the container launch
minimise the number of layers to speed up the container launch through speeding up the assembly process
order the layers from most static to least static so that there is less churn and depth to the image rebuild process eg: why rebuild layers 1-5 if only 6 requires building.
Image Definition Syntax
Consistency with Dockerfile syntax will make code easier to read. All directives and key words should be in upper case, leaving a clear distinction from image building tool syntax such as Unix commands.
All element names should be in lower case eg: image labels and tags, and arguments (ARG). The exception is environment variables (ENV) as it is customary to make them all upper case within a shell environment.
Be liberal with comments (lines starting with #). These should explain each step of the build and describe any external dependencies and how changes in those external dependencies (such as a version change in a base image, or included library) might impact on the success of the build and the viability of the target application.
# This application depends on type hints available only in 3.7+
# as described in PEP-484
ARG base_image="python:3.9"
FROM $base_image
...
Where multi-line arguments are used, sort them for ease of reading, eg:
RUN apt-get install -y \
apache2-bin \
binutils \
cmake
...
Build Context
The basic build process is performed by:
docker build -t <fully qualified tag for this image> \
-f path/to/Dockerfile \
project/path/to/build/context
The build context is a directory tree that is copied into the image build
process (just another container), making all of the contained files available to
subsequent COPY and ADD commands for pushing content into the target
image. The size of the build context should be minimised in order to speed up
the build process. This should be done by specifying a path within the
project that contains only the files that are required to be added to the
image.
Always be careful to exclude unnecessary and sensitive files from the image build context. Aside from specifying a build context directory outside the root of the current project, it is also possible to specify a .dockerignore file which functions like a .gitignore file listing exclusions from the initial copy into the build context. Never use ADD, COPY or ENV to include secret information such as certificates and passwords into an image eg: COPY id_rsa .ssh/id_rsa. These values will be permanently embedded in the image (even buried in lower layers), which may then be pushed to a public repository creating a security risk.
Minimise Layers
Image builds tend to be highly information dense, therefore it is important to keep the scripting of the build process in the Dockerfile short and succinct. Break the build process into multiple images as it is likely that part of your proposed image build is core and common to other applications. Sharing base images (and layers) between derivative images will improve download time of images, and reduce storage requirements. The Container Engine should only download layers that it does not already have - remember, the UnionFS shares the layers between running containers as it is only the upper most layer that is writable. The following example illustrates a parent image with children:
FROM python:3.9.5
RUN apt-get install -y libpq-dev \
postgresql-client-10
RUN pip install psycopg2 \
sqlalchemy
The image is built with docker build -t python-with-postgres:1.2.3 .. Now we have a base image with Python, Postgres, and SQLalchemy support that can be used as a common based for other applications:
FROM python-with-postgres:1.2.3
COPY ./app /app
...
Minimising layers also reduces the build and rebuild time - ENV, RUN, COPY, and ADD statements will create intermediate cached layers.
Multi-stage Builds
Within a Dockerfile it is possible to specify multiple dependent build stages. This should be used to reduce the final size of an image. For example:
FROM python-builder:latest AS builder
COPY requirements.txt .
RUN pip3 install -r requirements.txt
FROM python-runtime:latest
COPY --from=builder /usr/local /usr/local
...
This uses an imaginary Python image with all the development tools, and necessary compilers as a named intermediate image called builder where dependent libraries are compiled, and built and then the target image is created from an imaginary streamlined Python runtime image which has the built libraries copied into it from the original build, leaving behind all of the no longer required build tools.
Encapsulation of Data with Code
Avoid embedding configuration and data that your application requires in the container image. The only exceptions to this should be:
The configuration or data is guaranteed to be static
The configuration or data is tiny (kilo-bytes to few mega-bytes), well defined, and forms sensible defaults for the running application
To ignore this, will likely make your container implementation brittle and highly specific to a use case, as well as bloating the image size. It is better practice to mount configuration and data into containers at runtime using environment variables and volumes.
Base Images
Base images and image provenance will need to be checked in order to maintain the security and integrity of the SKA runtime systems. This is will include (but not limited to) automated processes for:
Code quality checking for target applications
Vulnerability scanning
Static application security testing
Dependency scanning
License scanning
Base image provenance tree
Ensuring that the base images and derivative images are safe and secure with verifiable provenance wll be important to the security of the entire platform, so it will be important to choose a base image that will pass these tests. To assist with this, the SKA will curate a set of base images for the supported language environments so that developers can have a supported starting position. Discuss your requirements with the Systems Team, so that they can be captured and supported in advance.
As a general rule, stable image tags should be used for base images that at least include the Major and Minor version number of Semantic Versioning eg: python:3.7. As curated base images come from trusted sources, this ensures that the build process gets a functionally stable starting point that will still accrue bug fixing and security patching. Do not use the latest tag as it is likely that this will break your application in future, and it gives no indication of the container developers last tested environment specification.
Reduce Image Size
Avoid installing unnecessary packages in your container image. Your production container should not automatically require a debugger, editor or network analysis tools. Leave these out, or if they are truly required, then create a derivative image from the standard production one explicitly for the purposes of debugging, and problem resolution. Adding these unnecessary packages will bloat the image size, and reduce the efficiency of image building, and shipping as well as unnecessarily expose the production container to potential further security vulnerabilities by increasing the attack surface.
RUN and packages
When installing packages with the RUN directive, always clean the package cache afterwards to avoid the package archives and other temporary files unnecessarily becoming part of the new layer - eg:
...
RUN \
apt-get update && \
apt-get install -y the-package && \
apt-get clean && \
rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/*
...
Ordering
Analyse the order of the build directives specified in the Dockerfile, to ensure that they are running from the lowest frequency changing to the highest.
Consider the following:
FROM python:3.9.5
ARG postgres_client="postgresql-client-10 libpq-dev"
RUN apt-get install -y $postgres_client
COPY requirements.txt .
RUN pip3 install -r requirements.txt
COPY ./app /app
...
Looking at the example above, during the intensive development build phase of an application, it is likely that the most volatile element is the ./app itself, followed by the Python dependencies in the requirements.txt file, then finally the least changeable element is the specific postgresql client libraries (the base image is always at the top).
Laying out the build process in this way ensures that the build exploits as much as possible the build cache that the Container Engine holds locally. The cache calculates a hash of each element of the Dockerfile linked to all the previous elements. If this hash has not changed then the build process will skip the rebuild of that layer and pull it from the cache instead. If in the above example, the COPY ./app /app step was placed before the RUN apt-get install, then the package install would be triggered every time the code changed in the application unnecessarily.
Volumes
Volumes definitions are not strictly required in order to make a container function, but it is still useful to add as it provides documentary evidence of expected behaviour.
FROM python:3.9.5
...
# configuration files are mounted at /etc/myconfig
# database storage is expected at /data
VOLUME ["/etc/myconfig", "/data"]
...
Ports
Ports, like Volumes definitions, are not strictly required in order to make a container function, but it is still useful to add as it provides documentary evidence of expected behaviour.
FROM python:3.9.5
...
# Application listens on 8080 for health check
EXPOSE 8080/tcp
...
Labels
Use the LABEL directive to add ample metadata to your image. This metadata is inherited by child images, so is useful for provenance and traceability.
...
LABEL \
author="Piers Harding <piers.harding@skao.int>" \
description="This image illustrates LABELs" \
license="Apache2.0" \
int.skao.team="Systems Team" \
int.skao.application="widget" \
int.skao.version="1.0.0" \
int.skao.repository="http://gitlab.com/ska-telescope/ska-project"
...
The following are recommended labels for all images:
author: name and email address of the author
description: a short description of this image and it’s purpose.
license: license that this image and contained software are released under
int.skao.team: the SKA team responsible for this image.
int.skao.application: the application that this image contains
int.skao.version: follows Semantic Versioning, and should be linked to the image version tag discussed below.
int.skao.repository: where the software pertaining to the building of this image resides
Arguments
Use arguments via the ARG directive to parameterise elements such as the base image, and versions of key packages to be installed. This enables reuse of the build recipe without modification. Always set default values, as these can be overridden at build time, eg:
ARG base_image="python:3.9.5"
FROM $base_image
RUN apt-get install -y binutls cmake
ARG postgres_client="postgresql-client-10 libpq-dev"
RUN apt-get install -y $postgres_client
...
The ARGs referenced above can then be addressed at build time with:
docker build -t myimage:1.2.3 \
--build-arg base_image="python:3.10.1" \
--build-arg postgres_client="postgresql-client-9 libpq-dev"
-f path/to/Dockerfile \
project/path/to/build/context
Note: the ARG postgres_client is placed after the apt-get install -y binutls cmake as this will ensure that the variable is bound as late as possible without invalidating the layer cache of that package install.
Environment Variables
Only set environment variables using ENV if they are required in the final image. ENV directives create layers and a permanent record of values that are set, even if they are overridden by a subsequent ENV directive. If an environment variable is required by a build step eg: RUN gen-myspecial-hash, then chain the export of the variable in the RUN statement, eg:
...
RUN export THE_HASH="wahoo-this-should-be-secret" \
&& gen-myspecial-hash \
&& unset THE_HASH
...
This ensures that the value is ephemeral, at least from the point of view of the resultant image.
ADD or COPY + RUN vs RUN + curl
ADD and COPY are mostly interchangeable, however ADD my-fancy.tar.gz /tmp might not do what you expect in that it will auto-extract the archive at the target location.
COPY is the preferred mechanism as this does not have any special behaviours.
Be clear of what the purpose of the COPY or ADD statement is. If it is a dependency only for a subsequent build requirement, then consider replacing with RUN eg:
...
RUN \
mkdir /usr/local/dist && cd /usr/local/dist && \
curl -O https://shibboleth.net/downloads/identity-provider/3.2.1/shibboleth-identity-provider-3.2.1.tar.gz && \
tar -zxf shibboleth-identity-provider-3.2.1.tar.gz && \
rm shibboleth-identity-provider-3.2.1.tar.gz
...
The above example downloads and installs the software archive, and then removes it within the same image layer, meaning that the archive file is not left behind to bloat the resultant image.
USER and WORKDIR
It is good practice to switch the container user to a non privileged account when possible for the application, as this is good security practice, eg: RUN groupadd -r userX && useradd --no-log-init -r -g userX userX, and then specify the user with USER userX[:userX].
Never use sudo - there should never be a need for an account to elevate permissions. If this seems to be required then please revisit the architecture, discuss with the Systems Team and be sure of the reasoning.
WORKDIR is a helper that sets the default directory at container launch time. Aside from being good practice, this is often helpful when debugging as the path and context is already set when using docker exec -ti ....
ENTRYPOINT and CMD
ENTRYPOINT and CMD are best used in tandem, where ENTRYPOINT is used as the default application (fully qualified path) and CMD is used as the default set of arguments passed into the default application, eg:
...
ENTRYPOINT ["/bin/cat"]
CMD ["/etc/hosts"]
...
It is best to use the ["thing"] notation as this is the exec format ensuring that proper signal propagation occurs to the containerised application.
It is often useful to create an entry point script that encapsulates default flags and settings passed to the application, however, still ensure that the final application launch in the script uses exec /path/to/my/app ... so that it becomes PID 1.
ONBUILD and the undead
ONBUILD is a powerful directive that enables the author of an image to enforce an action to occur in a subsequent derivative image build, eg:
FROM python:3.9.5
RUN pip3 install -r https://example.com/parent/image/requirements.txt
ONBUILD COPY ./app ./app
ONBUILD RUN chmod 644 ./app/bin/*
...
Built with docker build -t myimage:1.0.0-onbuild .
In any child image created FROM myimage:1.0.0-onbuild ..., the parent image will seemingly call back from the dead and execute statement COPY ./app ./app and RUN chmod 644 ./app/bin/* as soon as the FROM statement is interpreted. As there is no obvious way to tell whether an image has embedded ONBUILD statements (without docker inspect myimage:1.0.0-onbuild), it is customary to add an indicator to the tag name as above: myimage:1.0.0-onbuild to act as a warning to the developer. Use the ONBUILD feature sparingly, as it can easily cause unintended consequences and catch out dependent developers.
Naming and Tagging
Image names should reflect the application that will run in the resultant container, which ideally ties in directly with the repository name eg: ska-tango-examples/powersupply:latest, is the image that represents the Tango powersupply device from the ska-tango-examples repository.
Images should be tagged with:
short commit hash as derived by
git rev-parse --verify --short=8 HEADfrom the parent repository eg: bbedf059. This is useful on each feature branch build as it uniquely identifies branch HEAD on each push when used in conjunction with Continuous Integration.When an image version for an application is promoted to production, it should be tagged with the application version (using Semantic Versioning). For the latest most major.minor.patch image version the ‘latest’ tag should be added eg: for a tango device and a released image instance with hash tag: 9fab040a, added version tags are:
1.13.2,1.13,1,latest- where major/minor/patch version point to the latest in that series.A production deployment should always be made with a fully qualified semantic version eg:
ska-tango-examples/powersupply:1.13.2. This will ensure that partial upgrades will not inadvertently make their way into a deployment due to historical scheduling. Thelatesttag today might point to the same hash as1.13.2, but if a cluster recovery was enacted next week, it may now point to1.14.0.
While it is customary for th Docker community at large to support image variants based on different image OS bases and to denote this with tags eg: python:<version>-slim which represents the Debian Slim (A trimmed Debian OS) version of a specific Python release, the SKA will endeavour to support only one OS base per image, removing this need as it does not strictly follow Semantic Versioning, and creates considerable maintenance overhead.
Within the SKA hosted Continuous Integration infrastructure, development and test images will be periodically purged from the repository after N months, leaving the last version built. All production images are kept indefinitely.
This way anyone who looks at the image repository will have an idea of the context of a particular image version and can trace it back to the source.
Image Tools
Any image build tool is acceptable so long as it adheres to the OCI image specification v1.0.0. The canonical tool used for this standards document is Docker 18.09.4 API version 1.39, but other tools maybe used such as BuildKit and img.
Development tools
Debuging tools, profilers, and any tools not essential to the running of the target application should not be included in the target application production image. Instead, a derivative image should be made solely for debugging purposes that can be swapped in for the running application as required. This is to avoid image bloat, and to reduce the attack surface of running containers as a security consideration. These derivative images should be named explicitly dev eg: ska-tango-examples/powersupply-dev:1.13.2.
Image Storage
All images should be stored in a Docker v2 Registry API compliant repository, protected by HTTPS. The SKA supported and hosted repositories are based on the Central Artefact Repository Container Registry available at artefact.skao.int .
All containerised software used within the SKA, will be served out of the hosted repository service. This will ensure that images are quality assured and always remain available beyond the maintenance life-cycle of third party and COTs software.
Image signing and Publishing
All images pushed to the SKA hosted repository must be signed. This will ensure that only trusted content will be launched in containerised environments. Docker Content Trust signatures can be checked with:
$docker trust inspect --pretty \
artefact.skao.int/ska-tango-images/ska-python-runtime:1.2.3
Signatures for artefact.skao.int/ska-tango-images/ska-python-runtime:1.2.3
SIGNED TAG DIGEST SIGNERS
1.2.3 3f8bb7c750e86d031dd14c65d331806105ddc0c6f037ba29510f9b9fbbb35960 (Repo Admin)
Administrative keys for artefact.skao.int/ska-tango-images/ska-python-runtime:1.2.3
Repository Key: abdd8255df05a14ddc919bc43ee34692725ece7f57769381b964587f3e4decac
Root Key: a1bbec595228fa5fbab2016f6918bbf16a572df61457c9580355002096bb58e1
Running Containerised Applications
As part of the development process for a containerised application, the developer must determine what the application interface contract is. Referring back to the Container Anatomy diagram above, a containerised application has a number of touch points with the underlying host through the Container Engine. These touch points form the interface and include:
Network - network and device attachment, hostname, DNS resolution
Volumes - persistent data and configuration files
Ports
Environment variables
Permissions
Memory
CPU
Devices
OS tuning, and ulimits
IPC
Signal handling
Command and arguments
Treatment of StdIn, StdOut, and StdErr
Usage documentation for the image must describe the intended purpose of each of these configurable resources where consumed, how they combine and what the defaults are with default behaviours.
Container Resources
Management of container resources is largely dependent on the specific Container Engine in use. For example, Docker by default runs a container application in it’s own namespace as the root user, however this is highly configurable. The following example shares devices, and user details with the host OS, effectively transparently running the application as the current user of the command line:
cat <<EOF | docker build -t mplayer -
FROM ubuntu:18.04
ENV DEBIAN_FRONTEND noninteractive
RUN \
apt-get update && \
apt-get install mplayer -y && \
apt-get clean && \
rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/*
ENTRYPOINT ["/usr/bin/mplayer"]
CMD ["--help"]
EOF
docker run --rm --name the-morepork-owl \
--env HOME=${HOME} \
--env DISPLAY=unix$DISPLAY \
--volume /etc/passwd:/etc/passwd:ro \
--user $(id -u) \
--volume ${HOME}:${HOME} \
--workdir ${HOME} \
--volume /tmp/.X11-unix:/tmp/.X11-unix:ro \
--volume /etc/machine-id:/etc/machine-id:ro \
--volume /run/user/$(id -u):/run/user/$(id -u):ro \
-ti mplayer /usr/bin/mplayer https://www.doc.govt.nz/Documents/conservation/native-animals/birds/bird-song/morepork-song.mp3
Storage
As previously stated, all storage shared into a container is achieved through bind mounting. This is true for both directory mount points and individual files. While it is not mandatory to use the VOLUME directive in the image Dockerfile, it is good practice to do this for all directories to be mounted as it provides annotation of the image requirements.
These volumes and files can be populated with default data, but be aware they are completely masked at runtime when overlaid by a mount.
When adding a volume at runtime, consider whether write access is really required. As with the example above --volume /etc/passwd:/etc/passwd:ro ensures that the /etc/passwd file is read only in the container reducing the security concerns.
Network
containerised applications should avoid using --net=host (host only) based networking as this will push the container onto the running host network namespace monopolising any ports that it uses. This means that another instance of this container or any other that uses the same ports cannot run on the same host severely impacting on scheduling and resource utilisation efficiencies.
Permissions
Where possible, a containerised application should run under a specific UIG/GID to avoid privilege escalation as an attack vector.
It should be a last resort to run the container in privileged mode docker run --privileged ..., as there are very few use cases that will require this. The most notable are when a container needs to load kernel modules, or a container requires direct host resource access (such as network stack, or specialised device) for performance reasons. Running a container in this mode will push it into the host OS namespace meaning that the container will monopolise any resources such as network ports (see Network).
Configuration
Configuration of a containerised application should be managed primarily by:
configuration files
Avoid passing large numbers of configuration options on the command line, and service connection information that could contain secrets such as keys and passwords should not be passed as options, as these can appear in the host OS process table.
Configuration passed into a container should not directly rely on a 3rd party secret/configuration service integration such as vault, consul or etcd. If integration with these services are required, then a sidecar configuration provider architecture should be adopted that specifically handles these environment specific issues.
Appropriate configuration defaults should be defined in the image build as described in the earlier section on image environment variables, along with default configuration files. These defaults should be enough to launch the application into it’s minimal state unaided by specifics from the user. If this is not possible then the default action of the container should be to run the application with the --help option to start the process of informing the user what to do next.
Memory and CPU
Runtime constraints for Memory and CPU should be specified, to ensure that an application does not exhaust host resources, or behave badly next to other co-located applications, for example with Docker:
docker run --rm --name postgresdb --memory="1g" --cpu-shares="1024" --cpuset-cpus="1,3" -d postgres
In the above scenario, the PostgreSQL database would have a 1GB of memory limit before an Out Of Memory error occurred, and it would get a 100% share of CPUs 1 and 3. This example also illustrates CPU pinning.
Service Discovery
Although Container Orchestration is not covered by these standards, it is important to note that the leading Orchestration solutions (Docker Swarm, Kubernetes, Mesos) use DNS as the primary service discovery mechanism. This should be considered when designing containerised applications so that they inherently expect to resolve dependent services by DNS, and in return expose their own services over DNS. This will ensure that when in future the containerised application is integrated as part of an Orchestrated solution, it will conform to that architecture seamlessly.
Standard input, output, and errors
Container Engines such as Docker are implemented on the fundamental premise that the containerised application behaves as a standard UNIX application that can be launched (exec'ed) from the commandline.
Because of this, the application is expected to respond to all the standard inputs and outputs including:
stdin
stdout
stderr
signals
commandline parameters
The primary use case for stdin is where the container is launched replacing the entry point with a shell such as bash. This enables a DevOps engineer to enter into the container namespace for diagnostic and debug purposes. While it is possible to do, it is not good practice to design a containerised application to read from stdin as this will make an assumption that any scheduling and orchestration service that executes the container will be able to enact UNIX pipes which is not the case.
stdout and stderr are sent straight to the Container Engine logging system. In Docker, this is the logging sub-system which combines the output for viewing purposes with docker logs .... Because these logging systems are configurable, and can be syndicated into universal logging solutions, using stdout/stderr is used as a defacto standard for logging.
Logging
The SKA has adopted SKA Log Message Format as the logging standard to be used by all SKA software. This should be considered a base line standard and will be decorated with additional data by an integrated logging solution (eg: ElasticStack).
The following recommendations are made:
when developing containerised applications, the development process should scale from the individual unit on the desktop up to the production deployment. In order to do this, logging should be implemented so that stdout/stderr is used, but is configurable to switch the emission to syslog
log formatting must adhere to SKA Log Message Format
testing should include confirmation of integration with the host syslog, which is easily achieved through bind mounting
/dev/logwithin the syslog standard, the message portion should be enriched with JSON structured data so that the universal logging solution integrated with the Container Engine and/or Orchestration solution can derive greater semantic meaning from the application logs