Kubernetes based Runners Architecture
GitLab runners are orchestrated by a Kubernetes cluster. They could be deployed to any Kubernetes clusters using the gitlab_runner ansible collection. The main architecture is illustrated below.
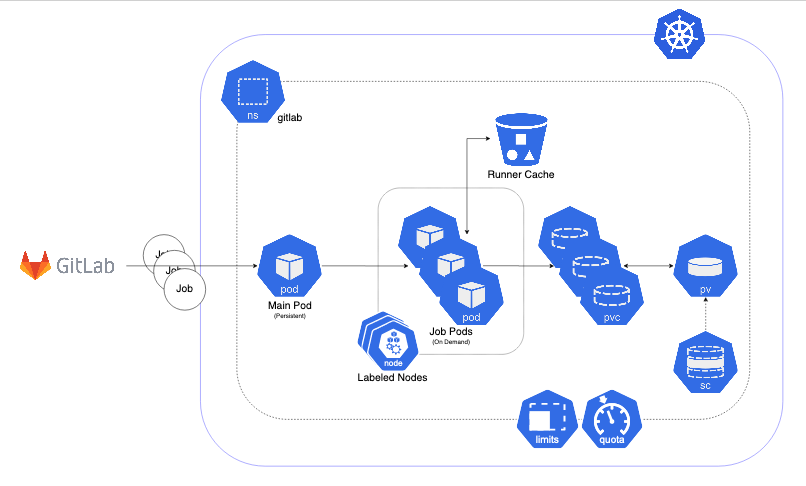
Features
The main runner pod is deployed with Helm Chart under gitlab namespace with the repository.
Main runner pod is registered to ska-telescope group shared runners with configurable tags.
The main pod picks up GitLab Jobs and creates on-demand pods. This is configured using helm chart values file/or config.toml file of GitLab runners below.
Runners are scaled according to configuration.
Runners have resource limits i.e. cpuRequests, memoryRequests, memoryLimit.
Runners are running in nodes that are specifically labelled for ci/cd jobs.
Runners share a cache between them that is used to speed up the job times.
Dedicated BuildX worker pools provide multi-platform container builds through Docker BuildX (
ska-buildxtag).Specific runners exist for Kubernetes Deployment/Integration testing. (ska-k8s tag).
Docker support
Kubernetes support
With this approach, GitLab Runners are proven to be a viable option to be used in a cluster with auto-scaling and easy management. Docker Support
Docker can be used in the CI/CD jobs as with the normal runners. Note that: docker-compose cannot be used in conjunction with Kubernetes! You should follow the instruction on the developer portal to set up your repo.
To elevate some of the security concerns listed below with using Docker in Docker, another docker daemon is deployed in the nodes. This daemon then used as default docker-daemon in the runner pods. Kubernetes Support
Kubernetes clusters could be created in ci/cd jobs. These clusters are created on the ci-worker nodes and destroyed at the end of the job.
Note: in order to run deploy clusters, the account permissions need to be set up correctly for the runner services.
STFC Cloud Kubernetes Clusters
For development purposes, STFC-backed clusters are the preferred method of deployment and testing, using Gitlab to deploy workloads into clusters. Currently we have two clusters, both with the same capabilities (Gitlab and Vault integrations, Binderhub, etc):
techops - Main cluster used by the whole project for CI/CD. It has limited support for GPUs, being mainly used to build artefacts that require GPUs
dp - Cluster used by the DP ART that provides more GPUs to run actual workloads
Note
The runner tags below are automatically set for SKAO provided templates (Pipeline Machinery) using variables. Therefore, we don’t advise to manually set them but use the variables below when needed:
SKA_DEFAULT_RUNNER: The default runner to be used. Defaults to ska-default
SKA_K8S_RUNNER: The default k8s runner to be used. Defaults to ska-k8s
SKA_GPU_RUNNER: The default GPU runner to be used. Defaults to ska-gpu-a100.
STFC Techops
Nodes
Type |
Amount |
CPU |
Memory |
GPU |
Kubernetes |
Version |
OS |
Version |
Kernel |
Version |
GPU |
Driver |
Version |
|||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
stfc-techops-production-cicd-md-0* |
51 |
16 |
64GiB |
0 |
v1.32.2 |
Ubuntu |
22.04.1 |
LTS |
5.15.0-48-generic |
|||||||
stfc-techops-production-cicd-md-1* |
10 |
32 |
124GiB |
0 |
v1.32.2 |
Ubuntu |
22.04.1 |
LTS |
5.15.0-48-generic |
|||||||
stfc-techops-production-cicd-gpu-* |
1 |
30 |
100GiB |
1 |
(NVIDIA |
A100-PCIE-40GB) |
v1.32.2 |
Ubuntu |
22.04.1 |
LTS |
5.15.0-48-generic |
Cuda: |
12.7 |
Driver: |
565.57.01 |
|
stfc-techops-production-cicd-md-2-* |
1 |
64 |
230GiB |
0 |
v1.32.2 |
Ubuntu |
22.04.1 |
LTS |
5.15.0-48-generic |
|||||||
stfc-techops-production-cicd-buildx-md-0-* |
2 |
60 |
250GiB |
0 |
v1.32.2 |
Ubuntu |
22.04.1 |
LTS |
5.15.0-48-generic |
Runners
Runner |
Tag |
CPU |
Memory |
CPU Limit |
Memory Limit |
GPUs Available |
Concurrent Jobs |
ska-default-runner |
ska-default |
2 |
8G |
Unlimited (~16) |
16Gi |
0 |
100 |
ska-k8s-runner |
ska-k8s |
2 |
8G |
Unlimited (~16) |
16Gi |
0 |
42 |
ska-default-large-runner |
ska-default-large |
4 |
16G |
Unlimited (~30) |
32Gi |
0 |
5 |
ska-default-xlarge-runner |
ska-default-xlarge |
16 |
64G |
Unlimited (~30) |
128Gi |
0 |
2 |
ska-gpu-a100-runner |
ska-gpu-a100 |
2 |
8Gi |
Unlimited (~30) |
16Gi |
1 |
1 |
ska-buildx-runner |
ska-buildx |
16 |
32Gi |
Unlimited (~30) |
64Gi |
0 |
4 |
STFC DP
Nodes
Type |
Amount |
CPU |
Memory |
GPU |
Kubernetes Version |
OS Version |
Kernel Version |
GPU Driver Version |
|---|---|---|---|---|---|---|---|---|
stfc-dp-production-md-0 |
3 |
16 |
64GiB |
0 |
v1.32.2 |
Ubuntu 22.04.1 LTS |
5.15.0-48-generic |
|
stfc-dp-production-md-1 |
6 |
30 |
128GiB |
0 |
v1.32.2 |
Ubuntu 22.04.1 LTS |
5.15.0-48-generic |
|
stfc-dp-production-gpu-md-0 |
1 |
30 |
100GiB |
1 (NVIDIA A100-PCIE-40GB) |
v1.32.2 |
Ubuntu 22.04.1 LTS |
5.15.0-88-generic |
Cuda: 12.7 | Driver: 565.57.01 |
stfc-dp-production-gpu-md-1 |
1 |
28 |
210GiB |
2 (NVIDIA A100-PCIE-40GB) |
v1.32.2 |
Ubuntu 22.04.1 LTS |
5.15.0-88-generic |
Cuda: 12.7 | Driver: 565.57.01 |
Runners
Runner |
Tag |
CPU |
Memory |
CPU Limit |
Memory Limit |
GPUs Available |
Concurrent Jobs |
ska-dp-default-runner |
ska-dp-default |
2 |
8Gi |
Unlimited (~16) |
16Gi |
0 |
20 |
ska-dp-gpu-a100-runner |
ska-dp-gpu-a100 |
2 |
8Gi |
Unlimited (~16) |
16Gi |
3 |
20 |
Deploy to GPU nodes Using the GPU Runner
To run a job on a GPU runner, you can set the tag on your Gitlab job to one of the available GPU tags:
techops - ska-gpu-a100
dp - ska-dp-gpu-a100
Deploy pods to GPU nodes
If you have pods that need to run on GPU nodes, they must have special configurations:
POD configurations:
nodeSelector - This must be set to force the pods to be scheduled to GPU nodes.
node_selector:
"nvidia.com/gpu": "true"
tolerations: Given the node taint, the pods must tolerate that taint.
tolerations:
- key: "nvidia.com/gpu"
value: "true"
effect: "NoSchedule"
CONTAINER configurations: * resource limits and requirements - Needed to claim X amount of GPU instances, just like any other resource.
resources:
limits:
cpu: ...
memory: ...
nvidia.com/gpu: "<number of GPUs>"
requests:
cpu: ...
memory: ...
nvidia.com/gpu: "<number of GPUs>"
runtimeClass: You need to properly set the runtimeClass so that the container runtime knows what profile to use to bind GPUs to a pod container.
runtimeClassName: "nvidia"
Build multi-platform images Using the BuildX runner
The OCI build template was modified to now also support ARM architectures. It is provided in gitlab-ci/includes/oci-image.gitlab-ci.yml. It creates dedicated oci-image-build-armv5 and oci-image-build-armv8 jobs (beside the already existing `oci-image-build) that execute on the ska-buildx runners when the matching variables are enabled.
To build for ARMv5 add the include and variable to your .gitlab-ci.yml:
include:
- project: 'ska-telescope/templates-repository'
file: 'gitlab-ci/includes/oci-image.gitlab-ci.yml'
variables:
OCI_USE_PLATFORM_ARMV5: "true"
Switch to ARMv8 builds by setting OCI_USE_PLATFORM_ARMV8: "true" instead. Only one of the flags should be enabled at a time. When either flag is present, the template schedules the relevant job on the BuildX runner pool; the runner exposes the Docker BuildX plugins and pre-registers QEMU emulation for the requested platform.
Alternatively, if you are maintaining custom jobs, add the ska-buildx tag so the job lands on the BuildX-enabled pool:
tags:
- ska-buildx
The BuildX worker-group manifests and GitLab runner configuration can be reused from ska-ser-infra-machinery/resources/templates/buildx-* when onboarding another cluster or environment.