Troubleshooting
This page documents solutions to issues that arose while deploying PST in an integrated environment.
PST LMC and Core pods stuck in “Pending”
During the CSP / CBF / PST integration work in the Low PSI it was found that sometimes PST LMC and Core pods would stay in a “Pending” state as shown in the image below:
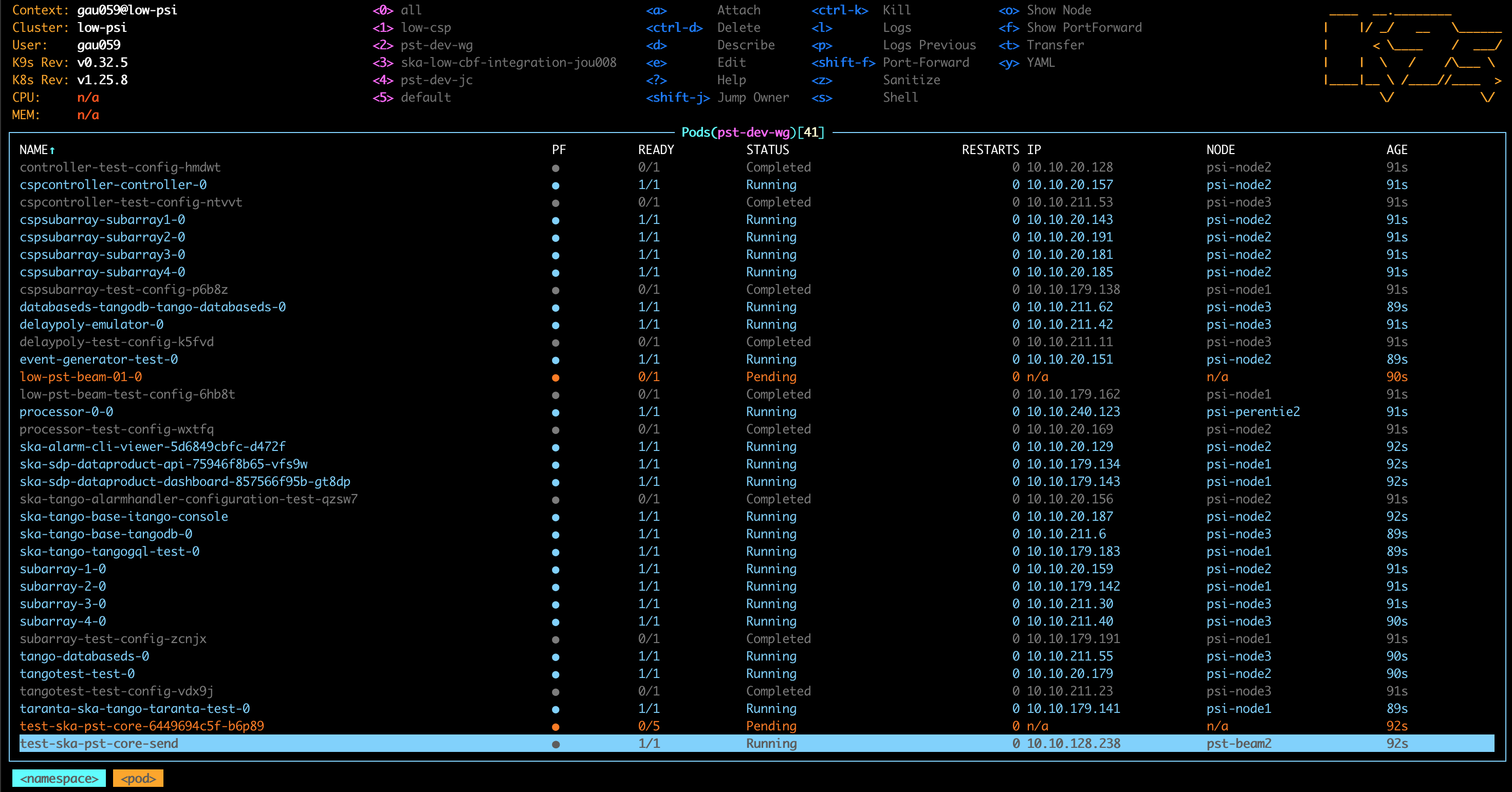
Performing
kubectl describe pod low-pst-beam-01-0
Returned
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 18s (x6 over 6m19s) default-scheduler 0/10 nodes are available: 1 node(s) didn't match pod affinity rules, 1 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: true}, 1 node(s) had untolerated taint {skao.int/dedicated: fpga-dev03}, 1 node(s) had untolerated taint {skao.int/dedicated: low-cbf-p4}, 1 node(s) had untolerated taint {skao.int/dedicated: perentie-old}, 1 node(s) had untolerated taint {skao.int/dedicated: perentie}, 1 node(s) had untolerated taint {skao.int/dedicated: pst}, 3 node(s) had volume node affinity conflict. preemption: 0/10 nodes are available: 10 Preemption is not helpful for scheduling.
When checking the PST Core pod we got the following:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 3m25s (x6 over 9m28s) default-scheduler 0/10 nodes are available: 1 node(s) didn't have free ports for the requested pod ports, 1 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: true}, 1 node(s) had untolerated taint {skao.int/dedicated: fpga-dev03}, 1 node(s) had untolerated taint {skao.int/dedicated: low-cbf-p4}, 1 node(s) had untolerated taint {skao.int/dedicated: perentie-old}, 1 node(s) had untolerated taint {skao.int/dedicated: perentie}, 1 node(s) had untolerated taint {skao.int/dedicated: pst}, 3 node(s) didn't match Pod's node affinity/selector. preemption: 0/10 nodes are available: 1 No preemption victims found for incoming pod, 9 Preemption is not helpful for scheduling.
The 1 node(s) didn’t have free ports for the requested pod ports part provided a clue for what was happening; this issue
only appears when using hostNetwork: true because the pod is trying to open a port that is already open on the server.
When using hostNetwork: false (the default value) this issue never arises. However, in an integration environment that
needs to accept data from an external Correlator Beam Former (CBF) the PST core pod needs to have hostNetwork: true.
When multiple instances of ska-pst` with hostNetwork: true` are deployed on the same server, in this case the
pst-beam2 in the psi-low environment, they will by default attempt to use the same port values,
causing the didn’t have free ports failure.
To resolve this a unique values file must be used for each deployment, and each file must specify unique host network port overrides. The following code snippet demonstrates how to override the PST Core ports; in this example, each value is offset from the default value by 5.
ska-pst:
core:
applications:
recv:
ports:
mgmt:
port: 18085
targetPort: 18085
datastream:
port: 32085
targetPort: 32085
smrb:
ports:
mgmt:
port: 18086
targetPort: 18086
dsp_disk:
ports:
mgmt:
port: 18087
targetPort: 18087
stat:
ports:
mgmt:
port: 18088
targetPort: 18088
dsp_ft:
ports:
mgmt:
port: 18089
targetPort: 18089
After applying this change PST pods got to a Running state within Kubernetes.
PST LMC Device fails to initialise
During the device init process, the PST LMC device tries to connect to the PST core signal processing applications via gRPC requests. We have seen this fail in the CSP / CBF / PST environment.
The following is a snippet of the log of the PST LMC pod:
Tango NamedDevFailedList exception
Exception for object simulationMode
Index of object in call (starting at 0) = 0
Severity = ERROR
Error reason = PyDs_PythonError
Desc : grpc._channel._InactiveRpcError: <_InactiveRpcError of RPC that terminated with:
status = StatusCode.UNAVAILABLE
details = "failed to connect to all addresses; last error: UNKNOWN: ipv4:130.155.198.233:8888: HTTP proxy returned response code 403"
debug_error_string = "UNKNOWN:Error received from peer {grpc_message:"failed to connect to all addresses; last error: UNKNOWN: ipv4:130.155.198.233:8888: HTTP proxy returned response code 403", grpc_status:14, created_time:"2024-07-03T07:09:42.788604737+00:00"}"
>
Origin : Traceback (most recent call last):
File "/usr/local/lib/python3.10/dist-packages/tango/server.py", line 159, in write_attr
return get_worker().execute(write_method, self, value)
File "/usr/local/lib/python3.10/dist-packages/tango/green.py", line 113, in execute
return fn(*args, **kwargs)
File "/app/python/src/ska_pst/lmc/component/pst_device.py", line 377, in simulationMode
self.component_manager.simulation_mode = value
File "/app/python/src/ska_pst/lmc/component/component_manager.py", line 177, in simulation_mode
self._simulation_mode_changed()
File "/app/python/src/ska_pst/lmc/beam/beam_component_manager.py", line 572, in _simulation_mode_changed
self._smrb_subcomponent.simulation_mode = self.simulation_mode
File "/app/python/src/ska_pst/lmc/component/subcomponent_manager.py", line 111, in simulation_mode
self._simulation_mode_changed()
File "/app/python/src/ska_pst/lmc/component/subcomponent_manager.py", line 317, in _simulation_mode_changed
self._update_api()
File "/app/python/src/ska_pst/lmc/component/subcomponent_manager.py", line 536, in _update_api
self._api.connect()
File "/app/python/src/ska_pst/lmc/component/process_api.py", line 491, in connect
_connect()
File "/usr/local/lib/python3.10/dist-packages/backoff/_sync.py", line 105, in retry
ret = target(*args, **kwargs)
File "/app/python/src/ska_pst/lmc/component/process_api.py", line 489, in _connect
self._connected = self._grpc_client.connect()
File "/app/python/src/ska_pst/lmc/component/grpc_lmc_client.py", line 237, in connect
self._service.connect(request)
File "/usr/local/lib/python3.10/dist-packages/grpc/_channel.py", line 1176, in __call__
return _end_unary_response_blocking(state, call, False, None)
File "/usr/local/lib/python3.10/dist-packages/grpc/_channel.py", line 1005, in _end_unary_response_blocking
raise _InactiveRpcError(state) # pytype: disable=not-instantiable
grpc._channel._InactiveRpcError: <_InactiveRpcError of RPC that terminated with:
status = StatusCode.UNAVAILABLE
details = "failed to connect to all addresses; last error: UNKNOWN: ipv4:130.155.198.233:8888: HTTP proxy returned response code 403"
debug_error_string = "UNKNOWN:Error received from peer {grpc_message:"failed to connect to all addresses; last error: UNKNOWN: ipv4:130.155.198.233:8888: HTTP proxy returned response code 403", grpc_status:14, created_time:"2024-07-03T07:09:42.788604737+00:00"}"
>
This error suggested that it was going through a HTTP proxy to get to the service
test-ska-pst-core.low-csp.svc.cluster.local:28081. The root cause of this was that the deployment had specified
a HTTP/HTTPS proxy without specifying a no_proxy value, this meant that the gRPC was attempting to go through
the HTTP proxy when the service was within the Kubernetes cluster and namespace. The following is a snippet of
the Helm values file that caused the issue.
global:
environment_variables:
- name: https_proxy
value: "http://delphoenix.atnf.csiro.au:8888"
- name: http_proxy
value: "http://delphoenix.atnf.csiro.au:8888"
# other values
The following code snippet shows how this was resolved:
global:
environment_variables:
- name: https_proxy
value: "http://delphoenix.atnf.csiro.au:8888"
- name: http_proxy
value: "http://delphoenix.atnf.csiro.au:8888"
- name: no_proxy
value: "cluster.local"
The no_proxy value should match the global variable cluster_domain which defaults to cluster.local. The
following shows how to set the proxy with a no_proxy when the cluster_domain is set.
global:
cluster_domain: psi-low.k8s.skao.int
environment_variables:
- name: https_proxy
value: "http://delphoenix.atnf.csiro.au:8888"
- name: http_proxy
value: "http://delphoenix.atnf.csiro.au:8888"
- name: no_proxy
value: "psi-low.k8s.skao.int"
PST errors during ConfigureScan
Generally the error for this should be a validation error. However, it is possible that the required bandwidth of the scan could cause an OutOfMemory limit error in Kubernetes which then results in RECV.CORE application being terminated by the Linux kernel.
When this happens the health check between PST LMC and the RECV.CORE application will fail and an exception will be logged in the LMC logs.
File "/app/python/src/ska_pst/lmc/component/grpc_lmc_client.py", line 211, in _wrapper
return func(client, *args, timeout=timeout, **kwargs)
File "/app/python/src/ska_pst/lmc/component/grpc_lmc_client.py", line 361, in configure_beam
self._service.configure_beam(request, timeout=timeout)
File "/usr/local/lib/python3.10/dist-packages/grpc/_channel.py", line 1181, in __call__
return _end_unary_response_blocking(state, call, False, None)
File "/usr/local/lib/python3.10/dist-packages/grpc/_channel.py", line 1006, in _end_unary_response_blocking
raise _InactiveRpcError(state) # pytype: disable=not-instantiable
grpc._channel._InactiveRpcError: <_InactiveRpcError of RPC that terminated with:
status = StatusCode.UNAVAILABLE
details = "Socket closed"
debug_error_string = "UNKNOWN:Error received from peer {created_time:"2025-06-11T07:50:53.031132144+00:00", grpc_status:14, grpc_message:"Socket closed"}"
>
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/app/python/src/ska_pst/lmc/component/grpc_process_api.py", line 214, in configure_beam
self._grpc_client.configure_beam(request=request, timeout=timeout)
File "/app/python/src/ska_pst/lmc/component/grpc_lmc_client.py", line 213, in _wrapper
_handle_grpc_error(e, timeout=timeout)
File "/app/python/src/ska_pst/lmc/component/grpc_lmc_client.py", line 266, in _handle_grpc_error
_handle_server_error(error, timeout)
File "/app/python/src/ska_pst/lmc/component/grpc_lmc_client.py", line 234, in _handle_server_error
raise ServiceUnavailable(error_code=error_code, message=message) from error
ska_pst.lmc.component.grpc_lmc_client.ServiceUnavailable
1|2025-06-11T07:50:53.040Z|WARNING|ParallelTaskThread_1|go_to_fault|grpc_process_api.py#411|tango-device:low-pst/beam/01|Error in trying to put remote service 'low-pst/beam/01/recv' in FAULT state.
Traceback (most recent call last):
File "/app/python/src/ska_pst/lmc/component/grpc_lmc_client.py", line 211, in _wrapper
return func(client, *args, timeout=timeout, **kwargs)
File "/app/python/src/ska_pst/lmc/component/grpc_lmc_client.py", line 361, in configure_beam
self._service.configure_beam(request, timeout=timeout)
File "/usr/local/lib/python3.10/dist-packages/grpc/_channel.py", line 1181, in __call__
return _end_unary_response_blocking(state, call, False, None)
File "/usr/local/lib/python3.10/dist-packages/grpc/_channel.py", line 1006, in _end_unary_response_blocking
raise _InactiveRpcError(state) # pytype: disable=not-instantiable
grpc._channel._InactiveRpcError: <_InactiveRpcError of RPC that terminated with:
status = StatusCode.UNAVAILABLE
details = "Socket closed"
debug_error_string = "UNKNOWN:Error received from peer {created_time:"2025-06-11T07:50:53.031132144+00:00", grpc_status:14, grpc_message:"Socket closed"}"
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/app/python/src/ska_pst/lmc/util/streaming_task.py", line 93, in start
for v in self._item_generator(self._abort_event):
File "/app/python/src/ska_pst/lmc/component/grpc_lmc_client.py", line 715, in perform_health_check
_handle_grpc_error(e, timeout=timeout)
File "/app/python/src/ska_pst/lmc/component/grpc_lmc_client.py", line 266, in _handle_grpc_error
_handle_server_error(error, timeout)
File "/app/python/src/ska_pst/lmc/component/grpc_lmc_client.py", line 234, in _handle_server_error
raise ServiceUnavailable(error_code=error_code, message=message) from error
ska_pst.lmc.component.grpc_lmc_client.ServiceUnavailable
1|2025-06-11T07:50:53.845Z|ERROR|Thread-23 (_run)|_handle_health_check_exception|api_subcomponent_manager.py#473|tango-device:low-pst/beam/01|Health check for RECV has raised an exception: . Restarting health check
1|2025-06-11T07:50:53.845Z|WARNING|Thread-30 (_run)|handle_health_state_change|beam_component_manager.py#1493|tango-device:low-pst/beam/01|RECV health state is in FAILED state. Putting 1 into FAILED state
During the development of v1.1.0 of PST the default memory limit was reduced but this affected
the deployments to environments run by TOPIC but this now has been reverted back to the default
value used in previous versions. The issue can be resolved by increasing the memory limits
for the core applications within the Helm values.yaml file when doing a Helm deployment. The following
code snippet shows what value to override. For more information about the Helm parameters check the
SKA PST Helm Chart Parameters page.
ska-pst:
core:
resources:
limits:
cpu: 1600m
memory: 6400Mi # <-- increase this value
requests:
cpu: 1600m
memory: 2000Mi