SKA PST STAT Architecture
Classes
The following diagram below shows the classes involved in the core software architecture of the SKA PST STAT component.

Class diagram showing main classes involved
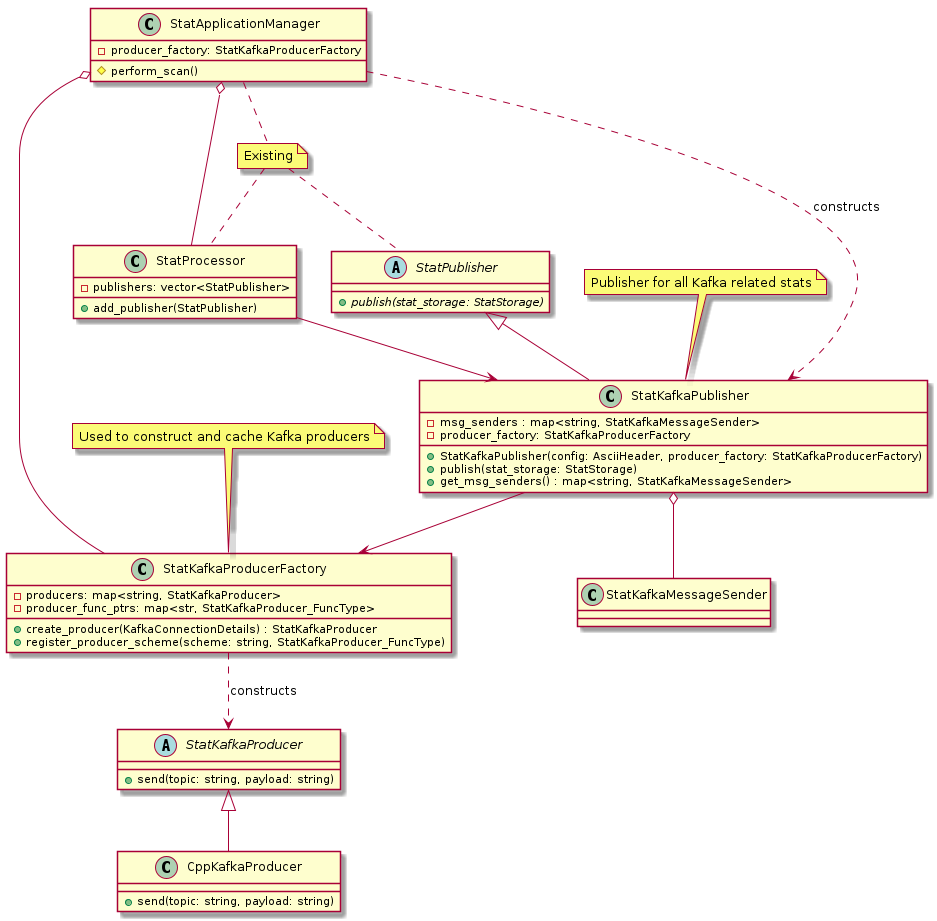
Class diagram showing StatApplicationManager and relationship with StatKafkaPublisher
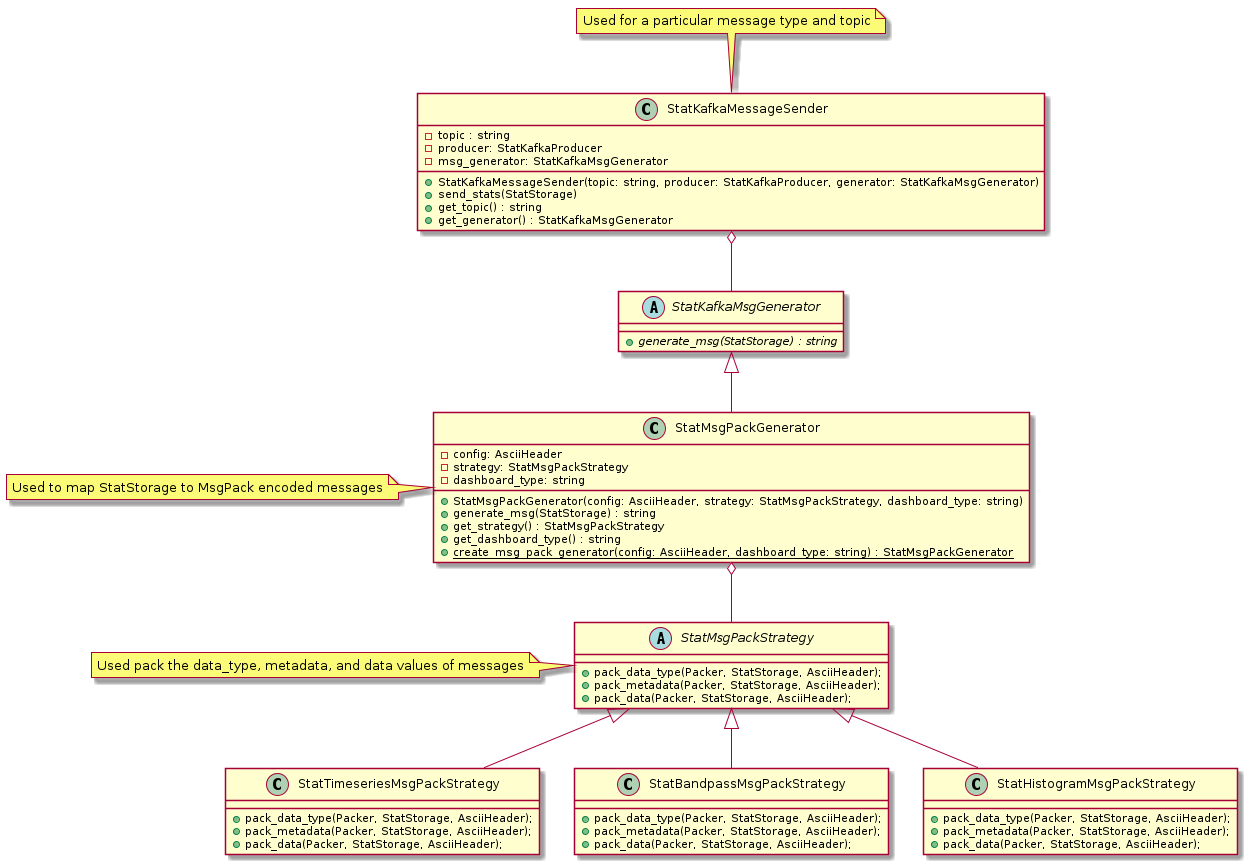
More detailed class diagram showing StatKafkaMessageSender and associated classes
StatProcessor
This is the core class to handle the processing of voltage data. It has been designed to work on data that is either coming from shared memory ring buffers during a scan or via memory mapped (mmap) files.
Applications, such as ska_pst_stat_core or ska_pst_stat_file_processor, that perform statistical calculations will use this class directly rather than performing their own orchestration.
During instantiation, this class will create a StatStorage instance with the correct sizes based on configuration. It creates instances of StatComputer and StatHdf5FileWriter passing along a shared pointer to the StatStorage instance.
This is not threadsafe, calls to the process method should ensure that the calls to it are threadsafe.
The StatProcessor asserts that there is data at least the length of one RESOLUTION bytes (i.e. NPOL * NDIM * NBITS * NCHAN * UDP_NSAMP / 8). If there is a fractional amount it will only calculate the statistics of an integer multiple of RESOLUTION bytes.
StatComputer
This class is the main class for performing the statistical computations.
This class is designed to be re-used between different blocks of data perform a calculation and updates the StatStorage struct.
See the StatHdf5FileWriter section for the output statistics that are calculated.
StatHdf5FileWriter
A utility class used for writing out the computed statistics to a file system. Instances of this class are passed a shared StatsStorage and the output path of where to write statistics to. Every call to write will serialise the StatStorage to a new HDF5 file.
HDF5 was chosen given it is an open standard, rather than creating new structured file format. Detailed information about the structure of these files is available at Statistics HDF5 File Format.
StatStorage
This class provides an abstraction to all of the storage required to hold the statistics products computed by the StatComputer. The class will be constructed with configuration parameters stored in a ska::pst::common::AsciiHeader with the following required parameters:
NPOL Number of polarisations in the input data stream (will always be 2).
NDIM Number of dimensions of each time sample (will always be 2).
NCHAN Number of channels in the input data stream.
NBIT Number of bits per sample in the input data stream.
NREBIN Number of bins in the re-binned input state histograms.
The class provides public methods to resize the storage and to reset all the values of the storage to zero. As documented in the StatStorage Class API, the class exposes all of the storage fields as 1, 2 or 3-dimension std::vector attributes of the appropriate types.
StatApplicationManager
This class is an implementation of the ska::pst::common::ApplicationManager class and is used by the ska_pst_stat_core process to manage the lifecycle of configuring the system and performing a scan.
When the application is in a ScanConfigured state this class will have created an instance of the StatProcessor class which will be used during a scan to perform the actual calculation of the statistics and writing the outputs to a file.
FileProcessor
This class is used by the ska_pst_stat_file_processor application to process a specific set of data and weights files. When the application runs it will read a config file into a ska::pst::common::AsciiHeader that is passed into the constructor of this class. When an instance of this class is created it will create an instance of a ska::pst::common::FileSegmentProducer, a StatProcessor, and a StatPublisher (specifically the StatHdf5FileWriter).
Kafka Dashboard Classes
The following are classes that relate specifically to the generation and publishing of MsgPack messages to send to Kafka topics
StatKafkaPublisher
This is a specific implementation of the existing StatPublisher class. The design uses only 1 StatKafkaPublisher but it creates separate instances of a StatKafkaMessageSender. This is so the StatApplicationManager doesn’t need to know about all the different types of dashboards, it just knows we may need to send stats to Kafka. In doing so we can evolve this publisher and the sender class independently the application manager, add new data types and MsgPack generators.
StatKafkaProducerFactory
This uses the factory pattern to create Kafka producers. In Kafka terminology, a producer is effectively a connection that sends messages to the Kafka server.
This factory is used to cache the connection to a Kafka instance if the same bootstrap server is applied, which would be the case for the all the topics for a given scan.
StatKafkaMessageSender
This class is similar to a publisher but has all the configuration and connections to Kafka it needs. The StatKafkaPublisher will create instances of this per dashboard type and provide the topic, Kafka producer and the MsgPack generator. This class is designed to be generic in the sense it doesn’t know what type of message or topic it is using. The StatKafkaPublisher will loop over the instances of this class every time its publish method is called and instances of this class will use the generator to generator message strings and then forward the messages to the Kafka producer.
StatKafkaProducer
This abstract class is used to represent the class of the library that is ultimately chosen. This allows using the bridge design pattern to allow swapping out of cppkafka for a different library.
CppKafkaProducer
This class is a concrete implementation of the StatKafkaProducer class that abstracts over the cppkafka::Producer class.
StatMsgPackGenerator
This class encodes the correct structure of the dashboard messages. The generate_msg takes the current StatStorage
can encodes common metadata as well as delegating to a StatMsgPackStrategy instance for packing of the
data_type, metadata, and data values.
This class and the associated strategy classes, do not have anything to do Kafka. This also allows for unit testing that we are able to encode the messages correctly.
StatMsgPackStrategy
This is a purely abstract class that is used as an interface by instances of StatMsgPackGenerator to populate the data_type,
metadata, and data values within the MsgPack message.
StatBandpassMsgPackStrategy
An implementation of the StatMsgPackStrategy that encodes the Bandpass data.
StatHistogramMsgPackStrategy
An implementation of the StatMsgPackStrategy that encodes the Histogram data.
StatTimeseriesMsgPackStrategy
An implementation of the StatMsgPackStrategy that encodes the Timeseries data.
Sequences
Processing of a block of data
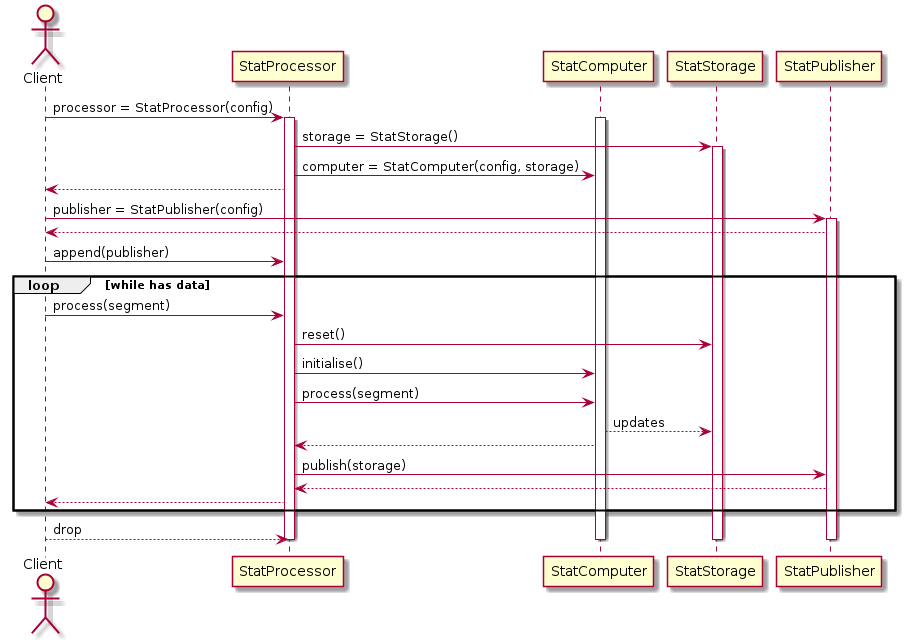
Sequence diagram for processing statistics with the StatProcessor class, common to both StatApplicationManager and FileProcessor sequences
Processing data during a scan
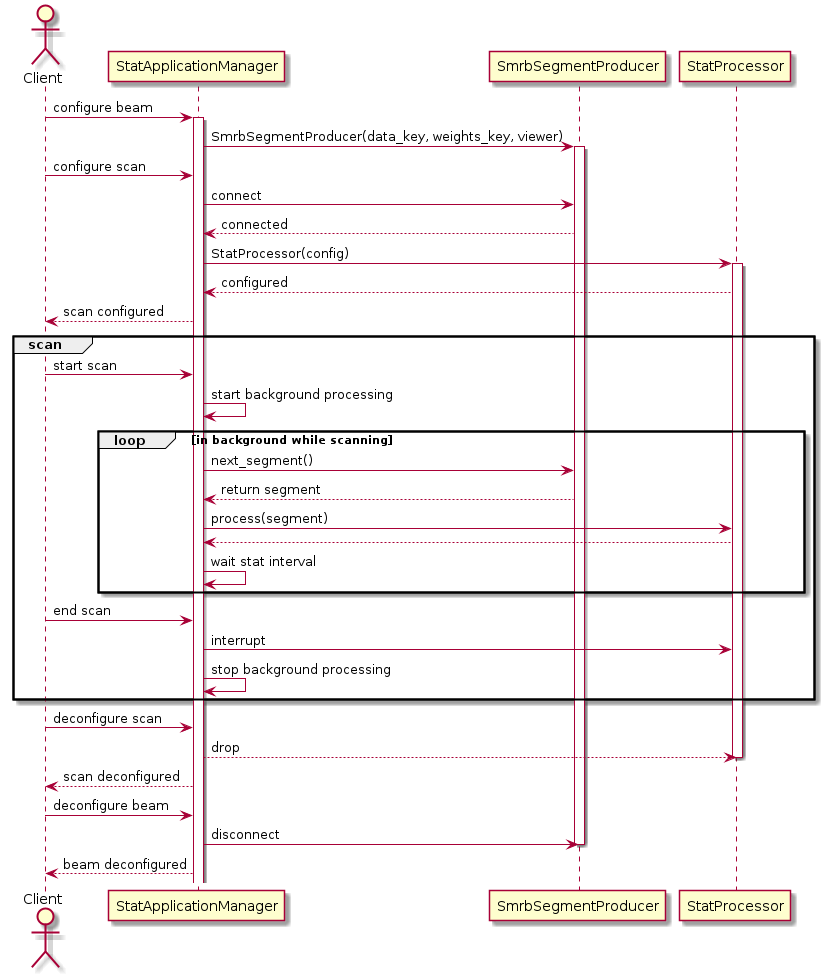
Sequence diagram for processing statistics during a scan with the StatApplicationManager class
Processing files after a scan
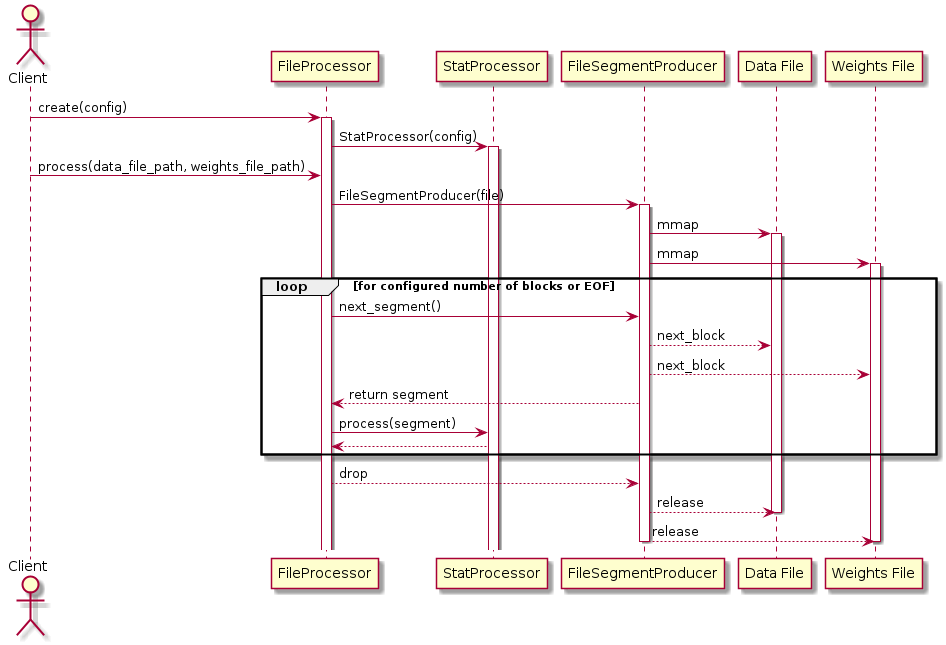
Sequence diagram for processing statistics from a file using the FileProcessor class
Publishing Kafka dashboard messages
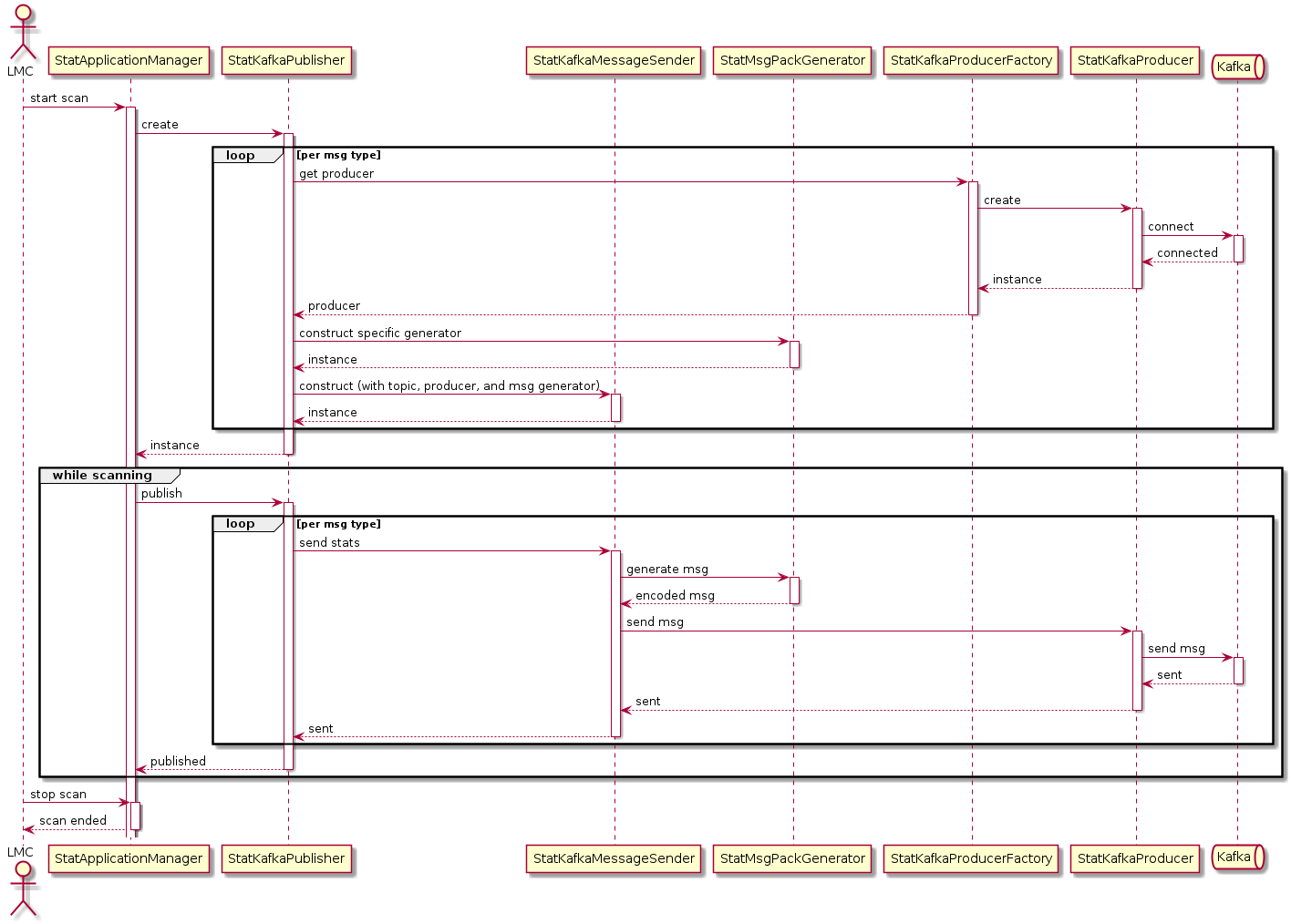
Sequence diagram for publishing Kafka dashboard messages