How to configure xtp uploading
This section describes how to create a configuration file that allows for uploading additional contextual information about a test execution result (see bdd helper scripts)
When to use it
When you require additional “context” information about a particular test execution result to be included in the upload.
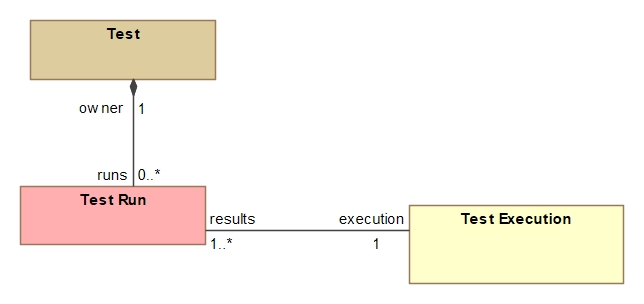
Currently an xray upload will populate a particular XRAY test with a reference to a test execution, allowing a user to view the current state of the test that was run (see diagram below).
However if you want to organise and manage your tests results according to a test plan, you need to associate the test execution with the test plan (see diagram below).
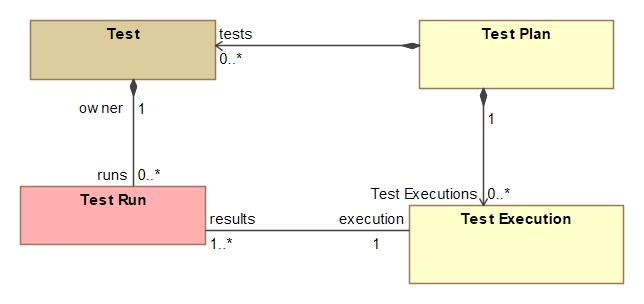
This requires the text execution to include a reference to the key identifying the test plan.
In addition you may also like to include in the test execution information regarding the environment, versions, time etc. All of these values can be provided together with the upload according the a specific configuration json file as per schema provided in the next section.
What you need before starting
Skallop package installed. The package will automatically install the scripts in the binary path.
How to use the feature
To use the feature you need to add an additional argument to the command invoking the script e.g:
xtp-xray-upload -f build/cucumber.json -i xtp_info.json
Jira project target and credentials
The upload module will by default use the ska Jira project: https://jira.skatelescope.org. However, should you wish to use a different target you can set it with the XRAY_UPLOAD_URL.`
The credentials used for authentication can either be supplied as a base64 encode value store in the JIRA_AUTH env variable, or as a username and password arguments in the command itself e.g:
xtp-xray-upload -f build/cucumber.json -i xtp_info.json -u $JIRA_USER -p $JIRA_PASS
Schema:
The schema of the info file corresponds to a “mapping” of values to populate the Test Execution fields with.
The table below lists all the fields in the json file and their corresponding use/meaning:
field |
meaning |
Ind |
|---|---|---|
project_id |
Jira Project Key containing the tests and test plans |
no |
name |
Used to create the test execution summary |
yes |
description |
Used to populate the description field |
no |
test_plans |
Reference to unique id/s identifying the test plan/s |
yes |
test_environments |
Populate the environment field |
yes |
labels |
Populate labels field |
yes |
versions |
Populate Fixed and Affect versions (optional) |
yes |
chart_info |
Points to a helm chart for use in desc field (optional) |
yes |
environmental_variables |
Points to a list of env values to put in the description field |
no |
test_report |
Points to the test report containing meta data about the test run |
no |
Field Names in the plural form must be set as lists. The Ind column in the schema above indicates if the field can be generated indirectly as explained below.
A value can either be obtained directly from the string value in the json file or it can be done indirectly derived from a user specified lookup mechanism as an json object.
There are currently three types of ways to read indirect values:
Insert the value according the contents of a given env variable (e.g. JOB_ID = 1 => use “JOB1”)
Insert the value according to the presence of a given keyword in the test report
Insert the value according to the presence of a given tag in the test results
Each option has a json specific schema as indicated by the object type:
select from an env var: SelectFromEnv
select from keywords var: SelectFromKeyword
select from keywords var: SelectFromTag
The schema for SelectFromEnv is as follows:
env: The name of an host environmental value
maps_to: a mapping that relates the specific value of the env variable to a given value
For example if you want to set a different name (the second field in the schema above) to write back to Jira based on the particular job running, and you have an existing env variable named JOB_NAME, you can use that as input for determining the value to be used. In other words if the JOB_NAME was test_low, you may want the name to be Test execution for Low, or if the JOB_NAME was test_mid you may want the name to be Mid and if the JOB_NAME is neither, Unknown. This would look like the following in the json file:
{...
"name": {
"env": "JOB_NAME",
"maps_to": {
"test_low" : "Low",
"test_mid" : "Mid",
"default: : "Unknown"
}
}
Note the use of “default” to indicate the value to use if env variable does not exist, or if it’s value is not one of the given options.
The schema for SelectFromKeyword is as follows:
select_from_keyword: a mapping that relates an output value if the given input keyword exists in the test report.
For example if you want to set a different name (the second field in the schema above) to write back to Jira based on the particular presence of the test plan ID (e,g. Test plan X: XTP-3615, Test plan Y: XTP-3612), you can use that as input for determining the value to be used. In other words if the test report contained a keyword, XTP-3615, you may want the name to be Test execution for Testplan X, or if the test report contained a keyword, XTP-3612 you may want the name to be Test execution for Testplan Y, The implicit assumption is that the particular keyword is mutually exclusive between the two instances. This would look like the following in the json file:
{...
"name": {
"select_from_keyword": {
"XTP-3615" : "Test execution for Testplan X",
"XTP-3612" : "Test execution for Testplan X",
"default: : "Unknown"
}
}
Note the use of “default” to indicate the value to use if none of the given keywords were found.
The schema for SelectFromTag is as follows:
select_from_tag: a mapping that relates an output value if the given input keyword exists in all of the tags from the test results.
For example if you want to set a different name (the second field in the schema above) to write back to Jira based on the particular presence of the test plan ID (e,g. Test plan X: XTP-3615, Test plan Y: XTP-3612), you can use that as input for determining the value to be used. In other words if each and everyone of the test result items contained a tag, XTP-3615, you may want the name to be Test execution for Testplan X, or if it contained a tag, XTP-3612 you may want the name to be Test execution for Testplan Y, The implicit assumption is that a tag’s presence in all tests is a mutually exclusive condition between the two instances (test sessions). This would look like the following in the json file:
{...
"name": {
"select_from_tag": {
"XTP-3615" : "Test execution for Testplan X",
"XTP-3612" : "Test execution for Testplan X",
"default: : "Unknown"
}
}
Note the use of “default” to indicate the value to use if none of the given keywords were found.
Example:
The snippet below provides an example of a json file that can be used:
{
"test_plans": [
"XTP-3348"
],
"name": {
"env": "CI_JOB_NAME",
"maps_to": {
"test_cluster": "Test Cluster Execution",
"default": "Test Execution"
}
},
"chart_info": {
"env": "DEPLOYMENT_CONFIGURATION",
"maps_to": {
"ska-mid": "charts/ska-mid/Chart.yaml",
"ska-low": "charts/ska-low/Chart.yaml",
"default": "charts/ska-mid/Chart.yaml"
}
},
"test_report": "build/report.json",
"project_id": "XTP",
"test_environments": [
"STFC-CI"
],
"labels": [
"STFC-CI"
],
"description": "Test results from https://gitlab.com/ska-telescope/ska-skampi\n",
"versions": [
{
"env": "DEPLOYMENT_CONFIGURATION",
"maps_to": {
"ska-mid": "ska-mid-0.9.1-dev",
"ska-low": "ska-low-0.6.0-dev"
}
}
],
"environmental_variables": [
"CI_JOB_URL",
"CI_COMMIT_TITLE",
"CI_JOB_STARTED_AT"
]
}
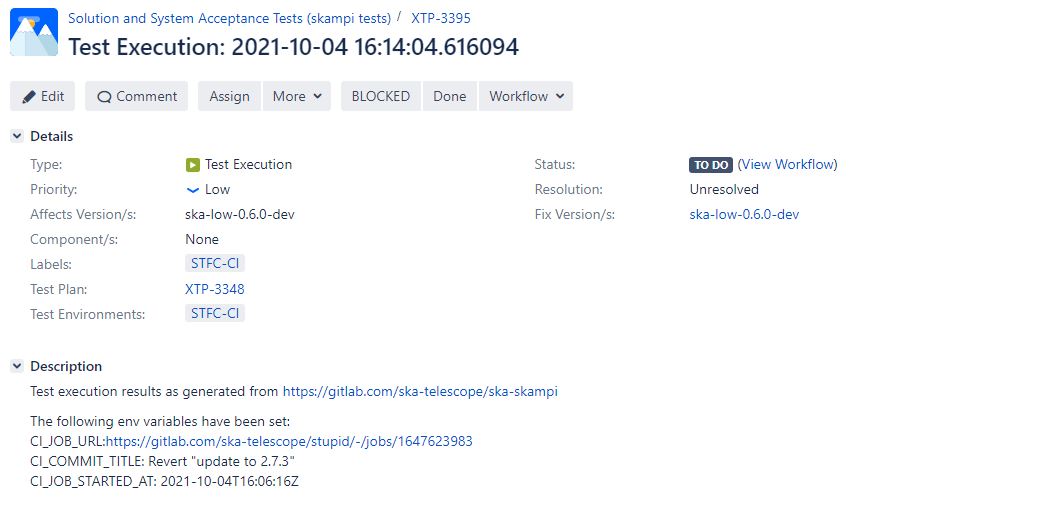
The result after uploading tests with above configuration will look roughly like the image below: